Generative Cross-modal Learning Network(GXN)论文阅读笔记。

CVPR 2018
文本提出将生成模型加入到文本-图像特征的提取中来进行跨模态检索,除了传统的在全局语义级别上进行的跨模态特征的提取之外,还引入了在局部级别上进行的跨模态特征的提取,这是基于两个生成模型:图像-文本和文本-图像生成模型来实现的。
总的来看,模型包含三个步骤:观察(look),想象(imagine)和匹配(match)。给定一个图片或者文本的查询,首先“观察”这个查询,提取一个抽象(abstract)的表示;然后,在另一个模态中“想象”查询目标(文本或图像)应该的“样子”,并且得到一个更加准确的 grounded representation,我们通过让一个模态的特征表示(待学习)来生成另一个模态的数据,然后将生成的数据与真实的数据进行比较;之后,使用相关度得分来匹配正确的图像-文本对,相关度得分是基于 grounded 和 abstract 表示的组合来计算的。
模型
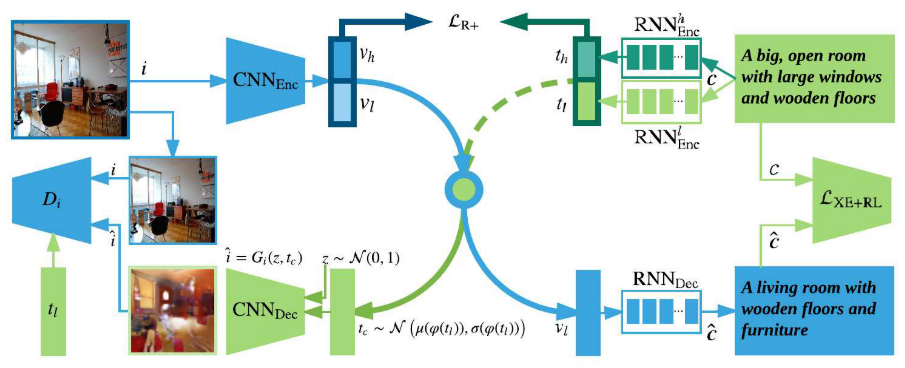
整个系统由三个训练过程组成:多模态特征Embedding,图像到文本特征生成过程和文本到图像特征生成对抗学习过程。
多模态特征Embedding和其他跨模态特征表示一样,都是将不同模态的数据映射到一个共同的空间中,然而在这里的不同之处是,每个模态的特征这里都学习了两种表示,一个是$(v_h, t_h)$,表示 High-level abstract features,$(v_l, t_l)$ 表示 detailed grounded features,多模态特征表示的目的就是使得$v_h/v_l$ 和 $t_h/t_l$ 的距离越近越好。这条训练过程主要由一个图像编码器 $CNN_{Enc}$ 和两个文本编码器 $RNN_{Enc}^h$ 和 $RNN_{Enc}^l$ 组成。
图像到文本训练过程,即上图中的蓝色路径,是为了从图像特征 $v_l$ 中生成一个句子特征,由图像编码器 $CNN_{Enc}$ 和一个句子解码器 $RNN_{Dec}$ 组成。
文本到图像训练过程,即上图中的绿色路径,是为了从文本特征 $t_l$ 中生成一个图像。这里使用生成对抗模型来训练,由生成器(解码器)$CNN_{Dec}$ 和判别器 $D_i$ 组成。
在测试阶段,${v_h, v_l}$ 和 ${t_h, t_l}$ 用作最终的跨模态检索的特征表示。
跨模态特征Embedding
将图像和文本映射到同一表示空间后,使用基于对的排序损失来学习模型的参数。给定一个图像-文本对 $(i,c)$,其中 $i$ 是图像,$c = (w_0, …,w_{T-1})$ 是对应图像的文本描述,$w_i$为one-hot向量,通过分布式表示将 $c$ 中的每个词变为 $\mathbf{W}_e w_i$,其中 $\mathbf{W}_e$ 为词的分布式表示矩阵,可以随机初始化,或者使用预训练的结果,如word2vec。
然后使用两个序列化的句子编码器(如GRU)来得到句子的表示。
对于图像的编码,使用ImageNet预训练的CNN来提取。
\[v_k = P_v^k(CNN_{Enc}(i;\theta_i)), \\ t_k = P_t^k(RNN_{Enc}^k(c;\theta_c^k))\]其中,$k \in {h,l}$,$\theta$ 为各个编码器的参数,$P$ 是线性变换函数,将编码之后的向量映射到公共的表示空间。
我们将$(i,c)$作为正例,$i’$ 和 $c’$ 为负例,我们的目标是真实图像-文本对的相似度要比所有负例对的相似度都要大,排序损失为
\[\mathcal{L}_{Rank} = \frac1N\sum_{n=1}^N\mathcal{L}_R(i_n, c_n)\]单个样本的损失$\mathcal{L}_R$为:
\[\begin{align} \mathcal{L}_R = &\sum_{t'}[\alpha - s(t,v) + s(t',v)]_+ + \\ & \sum_{v'}[\alpha - s(t,v) + s(t,v')]_+ \end{align}\]- $\alpha$ 为 margin
- $s(t,v) = -|\max (0, v-t)|^2$ 为 order-violation penalty,是相似度函数
- $[x]_+$ 表示 $\max(x,0)$
考虑到跨模态特征有两种不同的表示 $(t_h, v_h)$ 和 $(t_l, v_l)$,排序损失改为
\[\begin{align} \mathcal{L}_{R^+} = &\sum_{t'}[\alpha - s^*(t_{h,l}, v_{h,l}) + s^*(t_{h,l}', v_{h,l})]_+ + \\ &\sum_{v'}[\alpha - s^*(t_{h,l}, v_{h,l}) + s^*(t_{h,l}, v_{h,l}')]_+ \end{align}\]- $s^*(t_{h,l},v_{h,j}) = \lambda s(t_h,v_h) + (1-\lambda)s(t_l, v_l)$ 是新的相似度函数
图像到文本生成特征学习
Image-to-text(i2t)的目的就是使得图片特征 $v_l$ 能够生成与真实图像描述相似的句子。先将图片通过 $CNN_{Enc}$ 编码,然后将编码得到的特征通过 $RNN_{Dec}$ 解码成句子,和传统基于RNN的文本生成模型一样,我们首先用交叉熵损失(XE)来训练模型:
\[\mathcal{L}_{xe} = - \sum_{t=0}^{T-1} \log p_{\theta_t}(w_t|w_{0:t-1},v_l;\theta_t)\]- $w_t$ 为真实描述中的词
- $p_{\theta_t}(w_t|w_{0:t-1},v_l)$ 是在参数 $\theta_t$ 条件下,生成 $w_t$ 的概率
然而,交叉熵损失是词级别的损失,由此训练的模型可能会有 exposure bias problem 和 loss-evaluation mismatch problem,因此将整个句子的损失也考虑进去,令负期望奖励最小化:
\[\mathcal{L}_{rl} = -\mathbb{E}_{\tilde c \sim p_{\theta_t}}[r(\tilde c)]\]- $\tilde c = (\tilde w_0, \cdots, \tilde w_{T-1})$ 是从解码器采样得到的词序列
- $r(\tilde c)$ 是生成句子的奖励,通过标准的评价方法如BLEU或CIDEr来比较生成的句子与真实的句子
通过强化学习的方式,使用蒙特卡洛方法从 $p_{\theta_t}$ 中对 $\tilde c$ 进行采样,得到上式的梯度为
\[\begin{align} \nabla_{\theta_t}\mathcal{L}_{rl} &= -\mathbb{E}_{\tilde c \sim p_{\theta_t}}[r(\tilde c) \cdot \nabla_{\theta_t} \log p_{\theta_t}(\tilde c)] \\ & \approx -r(\tilde c)\nabla_{\theta_t} \log p_{\theta_t}(\tilde c) \\ & \approx -(r(\tilde c) - r_b) \nabla \log p_{\theta_t}(\tilde c) \end{align}\]- $r_b$ 为基准参数,用来在不改变梯度的情况下减小方差
在训练的早期阶段,直接优化上式无法保证生成的句子的流畅性和可读性。因此使用两种损失的混合:
\[\mathcal{L}_{xe+rl} = (1-\gamma)\mathcal{L}_{xe} + \gamma\mathcal{L}_{rl}\]为了退火和加速收敛,首先优化XE损失$\mathcal{L}_{xe}$ ,然后再转为优化上式的联合损失。
文本到图像生成对抗特征学习
Text-to-image(t2i)的目标使得文本表示 $t_l$ 能够生成与真实图像相似的图像。
判别器的作用是为了能够从生成的样本$\rm{<fake\ image, true\ caption>}$和$\rm{<real \ image, wrong\ capion>}$中分辨出真实样本$\rm{<real\ image,true\ caption>}$。判别器$D_i$ 和生成器 $G_i$ ($CNN_{Dec}$)的目标函数如下:
\[\min_{G_i} \max_{D_i} V(D_i, G_i) = \mathcal{L}_{D_i} + \mathcal{L}_{G_i}\]判别损失和生成损失定义如下:
\[\begin{align} \mathcal{L}_{D_i} = &\mathbb{E}_{i\sim p_{data}}[\log D_i(i,t_l)]+\beta_f \mathbb{E}_{\hat i\sim p_G}[\log(1-D_i(\hat i,t_l))] + \\ & \beta_w\mathbb{E}_{i\sim p_{data}}[\log(1-D_i(i,t_l'))] \\ \mathcal{L}_{G_i} = &\mathbb{E}_{\hat i \sim p_G}[\log(1-D_i(\hat i, t_l))] \end{align}\]- $i$ 是$p_{data}$ 分布中的真实图像数据
- $\hat i = G_i(z,t_l)$ 是由生成器$G_i$ 在文本特征 $t_l$ 和噪声 $z$ 条件下生成的图像
- $z$ 是从固定的分布(如均匀分布或高斯分布)中采样得到
在实际实现中,将 $t_l$ 压缩成更低维的向量然后和 $z$ 组合。
然而,由于数据量的限制以及 $t_l$ 和 $z$ 之间的不平滑性,直接将 $t_l$ 和 $z$ 合并不能产生很好的结果。因此,引入一个新的变量 $t_c$,它由高斯分布 $\mathcal{N}(\mu(\varphi(t_l)), \sigma(\varphi(t_l)))$ 采样得到,$\varphi(t_l)$ 将 $t_l$ 压缩到一个更低的维度。
由此,在 $z$ 和 $t_c$ 的作用下生成 $\hat i =G_i(z,t_c)$,判别损失和生成损失修改如下:
\[\begin{align} \mathcal{L}_{D_i} = &\mathbb{E}_{i\sim p_{data}}[\log D_i(i,t_l)]+\beta_f \mathbb{E}_{\hat i\sim p_G}[\log(1-D_i(\hat i,t_l))] + \\ & \beta_w\mathbb{E}_{i\sim p_{data}}[\log(1-D_i(i,t_l'))] \\ \mathcal{L}_{G_i} = &\mathbb{E}_{\hat i \sim p_G}[\log(1-D_i(\hat i, t_l))] + \\ & \beta_s\mathcal{D}_{KL}(\mathcal{N}(\mu(\varphi(t_l)), \sigma(\varphi(t_l)))\ \|\ \mathcal{N}(0,1)) \end{align}\]- KL距离是为了增强隐数据结构的平滑度
具体算法如下:

实验
- 图像编码器:VGG19 和 ResNet152
- VGG19:倒数第二层全连接层作为提取的特征,维数4096
- ResNet152:在最后获得的图像特征之后加入一个平均池化层来提取全局图像特征,维数2048
- 句子编码器:双向GRU来获取 abstract 特征表示 $t_h$,GRU来获取 grounded 特征表示 $t_l$,维数都是1024
- 句子解码器:一层的GRU,维数1024
其他细节见论文。

