Self-Supervised Adversarial Hashing(SSAH)论文阅读笔记。

CPVR 2018
本文提出了一个自监督对抗哈希方法(SSAH)来进行跨模态检索,使用了两个对抗网络联合学习不同模态数据的高维特征和对应的Hash码,同时,整合一个自监督的语义网络通过多标签标注的形式发现语义信息,这些语义信息再被用作对抗网络的监督信息,来最大化两个模态间的语义相关度以及特征分布的一致性。
SSAH
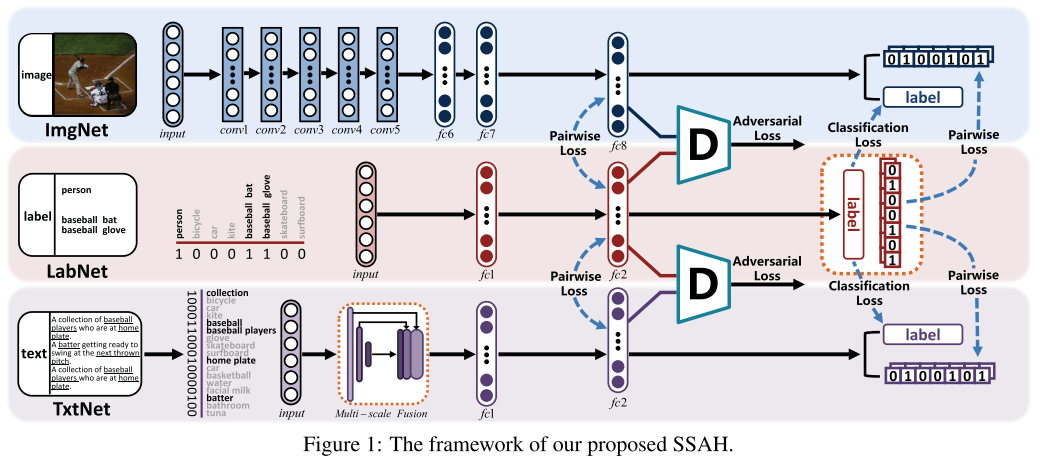
三个部分:
- 自监督语义生成网络 LabNet
- 图片相关的对抗网络 ImgNet
- 文本相关的对抗网络 TexNet
LabNet 就是从多标签标注中学习到语义特征,然后它可以被视为用于监督其他两个阶段的特征学习的公共语义空间。第一个阶段,在公共的语义空间中将不同网络生成的模态特征联系起来。考虑到深度神经网路的每个输出层都包含了语义信息,在公共的语义空间中将模态的特征联系起来,可以帮助提高模态之间的语义相关度。第二个阶段,把语义特征和模态特征同时送进两个判别网络。因此,在相同语义特征的监督下,两个模态的特征分布最终会趋于一致。
问题定义
- $O = {o_i}_{i=1}^n$ 表示有$n$个实例的跨模态数据
- $o_i = (v_i, t_i, l_i)$,其中$v_i \in \mathbb{R}^{1\times d_v}$ 和 $t_i \in \mathbb{R}^{1\times d_t}$ 分别表示图片和文本的特征向量
- $l_i = [l_{i1}, …, l_{ic}]$ 是对$o_i$的多标签标注,其中$c$为类别数目,当$o_i$属于第$j$类时,$l_{ij} = 1$,否则为0
- 所有数据的图片特征矩阵为$V$,文本特征矩阵为$T$,标签矩阵为$L$
- 两个实例之间语义相似度矩阵为$S$,当$o_i$和$o_j$至少有一个类别相同时,$S_{ij} = 1$
跨模态哈希的目标是学习两个模态的数据共同Hamming空间的Hash表示:$B^{v,t} \in {-1, 1}^K$,其中$K$是哈希码的长度,两个哈希码相似度通过Hamming距离来度量,即
\[dis_H(b_i, b_j) = \frac12(K - \langle b_i, b_j \rangle)\]其中,$\langle b_i, b_j \rangle$ 为内积运算。
因此,我们可以通过内积来衡量两个二进制码的相似度。给定相似矩阵$S$,有
\[p(S_{ij}|B) = \begin{cases} \delta(\Psi_{ij}), & S_{ij} = 1 \\ 1 - \delta(\Psi_{ij}), & S_{ij} = 0 \end{cases}\]其中,$\delta(\Psi_{ij}) = \frac{1}{1+e^{-\Psi_{ij}}}$,$\Psi_{ij} = \frac12 \langle b_i, b_j \rangle$ 。
即两个实例的内积越大,他们相似的概率就应该越大。
我们使用 ImgNet 和 TxtNet 来分别学习图片和文本的Hash函数,即$H^{v,t} = f^{v,t}(v,t;\theta^{v,t})$,同时,建立端到端的自监督语义网络 LabNet 将在相同语义空间的图片和文本的语义相关度建模,并且学习标签的表示$H^l = f^l(l;\theta^l)$ 。这里 $f^{v,t,l}$ 都是Hash函数,$\theta^{v,t,l}$ 是网络的参数,学到了 $H^{v,t,l}$ ,二进制码 $B^{v,t,l}$ 可以由符号函数生成,即
\[B^{v,t,l} = sign(H^{v,t,l}) \in \{-1, 1\}^K\]为了更容易理解,使用$F^{v,t,l} \in \mathbb{R}^{s\times n}$ 来表示图片、文本和标签的语义表示,$s$ 是语义空间的维度。实际上,$F^{v,t,l}$ 分别对应于相应神经网络的输出。
自监督语义生成网络
由于一个三元组$(v_i, t_i, l_i)$ 描述的都是第 $i$ 个实例,我们将$l_i$ 作为$v_i$ 和 $t_i$ 的自监督信息。
LabNet 最终的目标函数为
\[\begin{align} \min_{B^l, \theta^l, \hat{L}^l} \mathcal{L}^l &= \alpha \mathcal{J}_1 + \gamma \mathcal{J}_2 + \eta \mathcal{J}_3 + \beta \mathcal{J}_4 \\ &= -\alpha \sum_{i,j=1}^n \Big(S_{ij} \Delta_{ij}^l - \log(1+e^{\Delta_{ij}^l}) \Big) \\ &\quad -\gamma\sum_{i,j=1}^n\Big(S_{ij}\Gamma_{ij}^l - \log(1 + e^{\Gamma_{ij}^l})\Big) \\ &\quad + \eta\|H^l - B^l\|_F^2 + \beta \|\hat L^l - L\|_F^2 \\ &\quad s.t. \quad B^l \in \{-1, 1\}^K \end{align}\]其中
- \[\Delta_{ij}^l = \frac 12(F_{*i}^l)^T(F_{*j}^l)\]
- \[\Gamma_{ij}^l = \frac12(H_{*i}^l)^T(H_{*j}^l)\]
- $H^l$ 是预测的哈希码,$\hat L^l$ 是预测的标签
- $\alpha, \gamma, \eta$ 和 $\beta$ 都是超参
在上式中,$\mathcal{J}_1$ 和 $\mathcal{J}_2$ 是两个负对数似然函数。
特征学习
使用 LabNet 生成的语义信息作为监督信息,来学习 ImgNet 和 TxtNet 的特征表示。两个模型的目标函数如下
\[\begin{align} \min_{B^{v,t}, \theta^{v,t}} \mathcal{L}^{v,t} &= \alpha \mathcal{J}_1 + \gamma \mathcal{J}_2 + \eta \mathcal{J}_3 + \beta \mathcal{J}_4 \\ &= -\alpha \sum_{i,j=1}^n \Big(S_{ij} \Delta_{ij}^{v,t} - \log(1+e^{\Delta_{ij}^{v,t}}) \Big) \\ &\quad -\gamma\sum_{i,j=1}^n\Big(S_{ij}\Gamma_{ij}^{v,t} - \log(1 + e^{\Gamma_{ij}^{v,t}})\Big) \\ &\quad - \eta\|H^{v,t} - B^{v,t}\|_F^2 + \beta \|\hat L^{v,t} - L\|_F^2 \\ &\quad s.t. \quad B^{v,t} \in \{-1, 1\}^K \end{align}\]其中
- \[\Delta_{ij}^{v,t} = \frac 12 (F_{*i}^l)^T(F_{*j}^{v,t})\]
- \[\Gamma_{ij}^{v,t} = \frac 12 (H_{*i}^l)^T(H_{*j}^{v,t})\]
\(F_{*i}^l\) 和 \(H_{*l}^l\) 由语义网络学得,作为监督信息来引导 ImgNet 和 TxtNet 的学习,其他定义和之前的定义一致。
对抗学习
对图像和文本各设计一个判别器,对图像(文本)判别器,其输入是(图像)文本模态数据的特征向量和 LabNet 生成的语义特征向量,其输出是0或1。
判别器的目标函数如下:
\[\min_{\theta_{adv}\star,l} \mathcal{L}_{adv}^{\star,l} = \sum_{i=1}^{2\times n} \|D^{\star,l}(x_i^{\star l}) - y_i^{\star,l}\|_2^2, \ \star = v,t\]-
其中$x_i^{v,t,l}$ 为共同语义空间的语义特征,即$F_i^{v,t,l}$
-
$y_i^{v,t,l}$ 的定义暂未明确,Oooooops…

-
判别器其实起到分类的作用,将输入的语义特征分为“1”或“0”类
优化
三种哈希码由下式生成
\[B^{v,t,l} = sign(H^{v,t,l})\]我们令 $B = sign(H^v + H^t + H^l)$ 来训练模型,为语义相似的实例生成二进制码。
总体的目标函数为
\[\mathcal{L}_{gen} = \mathcal{L}^v + \mathcal{L}^t + \mathcal{L}^l \\ \mathcal{L}_{adv} = \mathcal{L}_{adv}^v + \mathcal{L}_{adv}^t\]将两者合起来,得到
\[\begin{align} (B,\theta^{v,t,l}) &= \mathop{\arg \min}_{B, \theta^{v,t,l}} \mathcal{L}_{gen}(B, \theta^{v,t,l}) - \mathcal{L}_{adv}(\hat \theta_{adv}) \\ \theta_{adv} &= \mathop{\arg \max}_{\theta_{adv}} \mathcal{L}_{gen}(\hat B, \hat \theta^{v,t,l}) - \mathcal{L}_{adv}(\theta_{adv}) \\ & s.t. \quad B \in\{-1, 1\}^K \end{align}\]学习算法如下

实现细节
详见论文。
实验
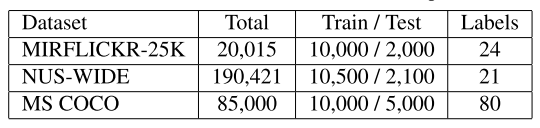
数据集
- MIRFLICKR-25K dataset
- NUS-WIDE dataset
- MS COCO dataset
- 80,000 训练集,40,000 验证集
- 随机选择验证集中的5000条数据作为测试集