跨媒体检索综述。


介绍
近年来,文本、图像、视频和语音等多媒体数据大量增加,而且用不同类型的数据描述同一件事情或话题也很常见,这些不同类型的数据被称为多模态数据。随着多模态数据量的不断增加,用户想要高效地在网上检索信息就变得十分困难。
目前,大多数检索策略都是基于单个模态的,包括关键词搜索和基于内容的搜索方法等,这些方法只能通过相似性搜索来查找相同模态的数据,比如文本检索、图像检索、音视频检索。因此,支持多模态相似性检索的模型在信息检索中有着很大的需求。
多模态检索是指将数据的一种类型作为查询,来查找相关的另一种类型的数据,比如以文搜图、以图搜文等。更宽泛的说,多模态检索中,用户可以提交任意模态的数据,通过检索得到相关的跨模态的不同类型的数据。
多模态检索的主要挑战是如何测量不同模态数据的相似度,而现在研究的主要目的就是使得跨模态检索的结果更加准确,并且可扩展性更高。
定义
设 $X,Y$ 为两个模态类型,训练数据\(\mathcal{D}_{tr} = \{X_{tr}, Y_{tr}\}\)其中 \(X_{tr} = \{\mathbf{x}_p\}_{p=1}^{n_{tr}}\) ,\(n_{tr}\) 是训练样本的数目,\(\mathbf{x}_p\) 是第 \(p\) 个训练数据, \(Y_{tr}\) 也是类似的定义。 \(\mathbf{x}_p\) 和 \(\mathbf{y}_p\) 有着相似的语义信息,\(\{c_p^X\}_{p=1}^{n_{tr}}\) 和 \(\{c_p^Y\}_{p=1}^{n_{tr}}\) 表示数据的语义分类。测试数据 \(\mathcal{D}_{te} = \{X_{te}, Y_{te}\}\) ,其中 \(X_{te} = \{\mathbf{x}_q\}_{q=1}^{n_{te}}\) , \(Y_{te} = \{\mathbf{y}_q\}_{q=1}^{n_{te}}\) ,跨模态信息检索的目标是计算两个不同模态数据的相似度,然后检索测试数据中对于任意模态的查询,与之相关的其他模态的数据。
研究现状
一般框架
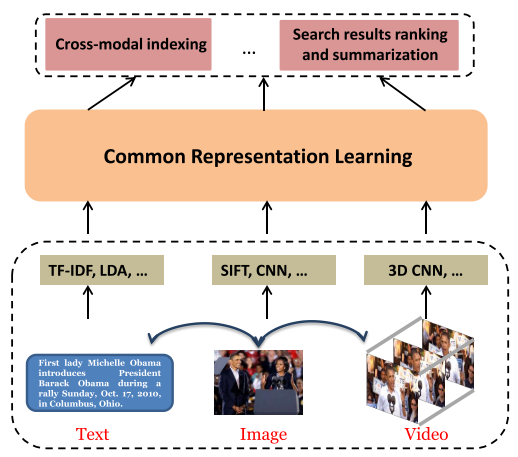
- 特征提取
- 跨模态相关建模(Cross-media correlation modeling):学习不同模态数据在同一个特征空间的表示
- 搜索结果排序等
实值表示学习方法
旨在学习不同模态数据在共同的实数空间里的表示。
非监督学习方法
非监督学习方法仅通过共现信息来学习跨模态数据的表示。共现信息指同时出现在一篇多模态文档中的不同模态的数据,他们的语义信息是相似的。
非监督学习方法又可以分为子空间学习方法(subspace learning methods)、话题模型(topic models)和深度学习方法。
子空间学习方法
学习被不同模态的数据共享的一个能够度量不同模态数据相似度的子空间,如下图所示。
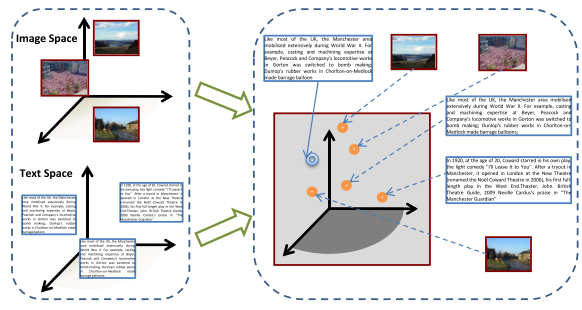
通过pair-wise的信息来学习跨模态数据共同的子空间。
Canonical Correlation Analysis(CCA)
对两个模态的数据$(x,y)$,学习两个向量$\mathbf{w}_x$和$\mathbf{w}_y$,使得两个模态的数据相关性最大,即
\[\max_{\mathbf{w}_x,\mathbf{w}_y} \frac{\mathbf{w}_x^T \Sigma_{xy}\mathbf{w}_y}{\sqrt{\mathbf{w}_x^T\Sigma_{xx}\mathbf{w}_x}\sqrt{\mathbf{w}_y^T\Sigma_{yy}\mathbf{w}_y}}\]其中$\Sigma$为协方差矩阵。
其他方法如Partial Least Squares (PLS)、Bilinear Model (BLM)、Cross-modal Factor Analysis (CFA)、Maximum Covariance Unfolding (MCU)、Collective Component Analysis (CoCA)、Greedy Dictionary Construction method和Sparse Projection Matrices。
话题模型
Correspondence LDA(Corr-LDA):将topic作为共享的隐变量
Topic-regression Multi-modal LDA(Tr-mm LDA):学习两个分开的topic的集合和一个回归模型
Multimodal Document Random Field(MDRF):学习一系列共享的topic
深度学习方法
Deep Canonical Corelation Analysis(DCCA)

Correspondence Autoencoder(Corr-AE)
基于对的方法
利用相似的对(或不相似的对)来学习不同模态数据间的距离度量函数,也成为异构度量学习(heterogeneous metric learning)
一般方法
Multi-View Neighborhood Preserving Projection(Multi-NPP)
Multiview Metric Learning with Global consistency and Local smoothness(MVML-GL)
Joint Graph Regularized Heterogeneous Metric Learning(JGRHML)
深度学习方法
Relational Generative Deep Belief Nets(RGDBN)
Modality-Specific Deep Structure(MSDS)
基于排序的方法
利用排序的列表来学习共同的表示,将跨模态检索当作排序学习问题
一般方法
Supervised Semantic Indexing(SSI)
Passive-Aggressive Model for Image Retrieval(PAMIR)
Latent Semantic Cross-Modal Ranking(LSCMR)
Ranking Canonical Correlation Analysis(RCCA)
深度学习方法
Dependency Tree Recursive Neural Networks(DT-RNNs)
deep Compositional Cross-Modal Learning to Rank($\mathbf{C}^2$MLR)
Cross-Modal Correlation learning with Deep Convolutional Architecture(CMCDCA)
监督学习方法
子空间学习方法
下图说明了无监督学习和有监督学习下子空间学习方法的不同,其中,形状相同表示类别相同,颜色相同表示模态相同
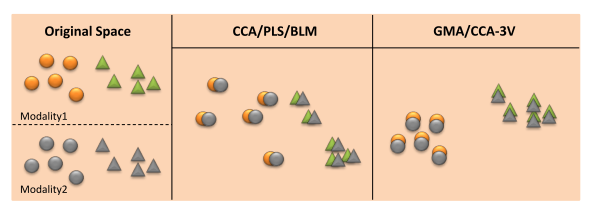
Generalized Multiview Analysis(GMA)
Cluster Canonical Correlation Analysis(cluster-CCA)
three-view CCA(CCA-3V)
mutil-label Canonical Correlation Analysis(ml-CCA)
话题模型
Document Neural Autoregressive Distribution Estimator(DocNADE)
Nonparametric Bayesian Upstream Supervised (NPBUS) multi-modal topic model
深度学习方法
Regularized Deep Neural Network(RE-DNN)
Multi-modal Deep Neural Network(MDNN)
二值表示学习方法(跨模态哈希)
为加快跨模态检索速度,二值表示学习方法将不同模态的数据映射到共同的Hamming空间表示,但是由于采用二进制编码,信息的损失对检索准确率有一定降低。
无监督学习
线性模型
Cross-View Hashing(CVH)
主要方法
Common Space Learning
统计相关分析方法
- 典型相关分析(Canonical correlation analysis,CCA)
- 无监督
- 没有使用语义分类标签
- Cross-modal Factor Analysis(CFA)
基于DNN的方法
跨模态图正则化方法
图正则化在半监督学习中被广泛应用,它将半监督学习问题转化成在部分带标签的图中打标签的问题。图中边的权重代表数据的相关度,图正则化的目标是预测没有标签的节点间的标签。
度量学习方法
通过相似/不相似的信息来学习距离度量方法
排序学习方法
将排序信息作为训练数据
字典学习方法
跨模态哈希方法
Cross-Media Similarity Measurement
基于Graph的方法
邻居分析方法
多模态数据集

-
- 包含2866图像-文本对
- 文本是一篇描述人、地点或事件的文章,图片和文本内容一致
- 每个图像-文本对都有一个标签

-
- 包含71,478图像-文本对,有353个类别
-
- Flickr8K的扩展,包含31,783张图像,每个图像有5个描述其内容的句子,每个句子相互独立
-
- 包含186,577张带标签的图片,每张图片都有用户标签
-
- 包含5011/4952(training/testing)图片-文本对,有20个类别
- 部分图像有多个标签
- 单标签图像-文本对有2808/2841(training/testing)个

-
- 20种类别
- 每个类别都有5种模态的数据,即每个类别都有250文本、250图像、25视频、50音频和25 3D模型
评价方法
Image-Text Retrieval
Mean Average Precision(MAP)
为计算MAP,首先计算average precision(AP)。假设检索最终返回了$R$ 篇文档,则AP定义为
\[AP = \frac 1T \sum_{r=1}^R P(r)\delta(r)\]- $T$ 是返回文档中与查询相关的文档的数目
- $P(r)$ 是返回文档中前$r$篇的准确率
- 当第$r$篇文档与查询相关时,$\delta(r) = 1$,否则$\delta(r)=0$。
对所有查询的AP值求平均即得MAP。MAP值越高,检索效果越好。

